Visual Thinking Lab
We study visual thinking:
how it works, and how
educaton + design can
make it work better.

We study visual thinking:
how it works, and how
educaton + design can
make it work better.
The visual system takes an incoming image of the world in terms of pixels, and turns it into an understanding in terms of objects and groups of objects. Imagine placing four coins on a table: two brown pennies and two silver dimes. You’ll see the objects arranged into groups – the brown ones and the silver ones. Yet we have no understanding of how this grouping occurs, hampering our ability to predict how these cues will be used in real-world applications. Our lab has been testing a deceptively simple possibility: that this grouping occurs simply because we pay attention to the relevant feature of the group (this possibility has also been proposed and supported by another lab). That is, grouping the brown objects is just attending everything in the visual field that is brown.
This account makes a unique prediction. If grouping occurs because we attend a single feature, then we should only be able to group by one feature at a time. That is, you should not be able to group both the pennies and the dimes simultaneously. Normally, you would never notice this lack of simultaneity, because every time you inspect an individual group, you attend to its features, so that you are unable to consciously check whether things that you are not attending are still grouped. This illusion is similar to the feeling that the light in your refrigerator is always on, because it is always on when you check.
We use two tasks to test this idea. The first is a searching task – if you create all color groups at once, you should be able to immediately find the one color that is or isn’t grouped, or the one color whose group creates a certain simple shape (e.g. a vertical stack of pennies). The second is enumeration – when asked to estimate the number of objects in a collection within a glance, your estimate should be influenced by the number of groups (Franconeri, Bemis, & Alvarez, 2009). Using both of these measures, we have found that color (as well as shape) grouping is surprisingly inefficient, consistent with the idea that grouping proceeds one group at a time, as would be predicted by the feature attention account (Franconeri, Xiao, Bemis, in preparation; Tam, Levinthal, & Franconeri, submitted).
We have also extended this idea to a form of grouping that we claim uses the same mechanism. ‘Common Fate’ grouping occurs when separate pieces of the visual field move in the same way, e.g. two parts of a car passing behind a tree, or a set of synchronized swimmers. Like color or shape grouping, there is no proposed mechanistic explanation for this type of grouping. Our hypothesis is that this grouping occurs in the same way, where we attend not a color, but a motion direction (previous work shows that we have this ability), resulting in attention to all parts of the visual field that share this feature (above figure). Again, this predicts that we can only create one group at a time, conflicting with our intuitions. Using a visual search task, we again showed that these perceptions are wrong (Levinthal & Franconeri, 2011), and that attention to a motion direction may allow us to create common fate groups, though only one at a time.
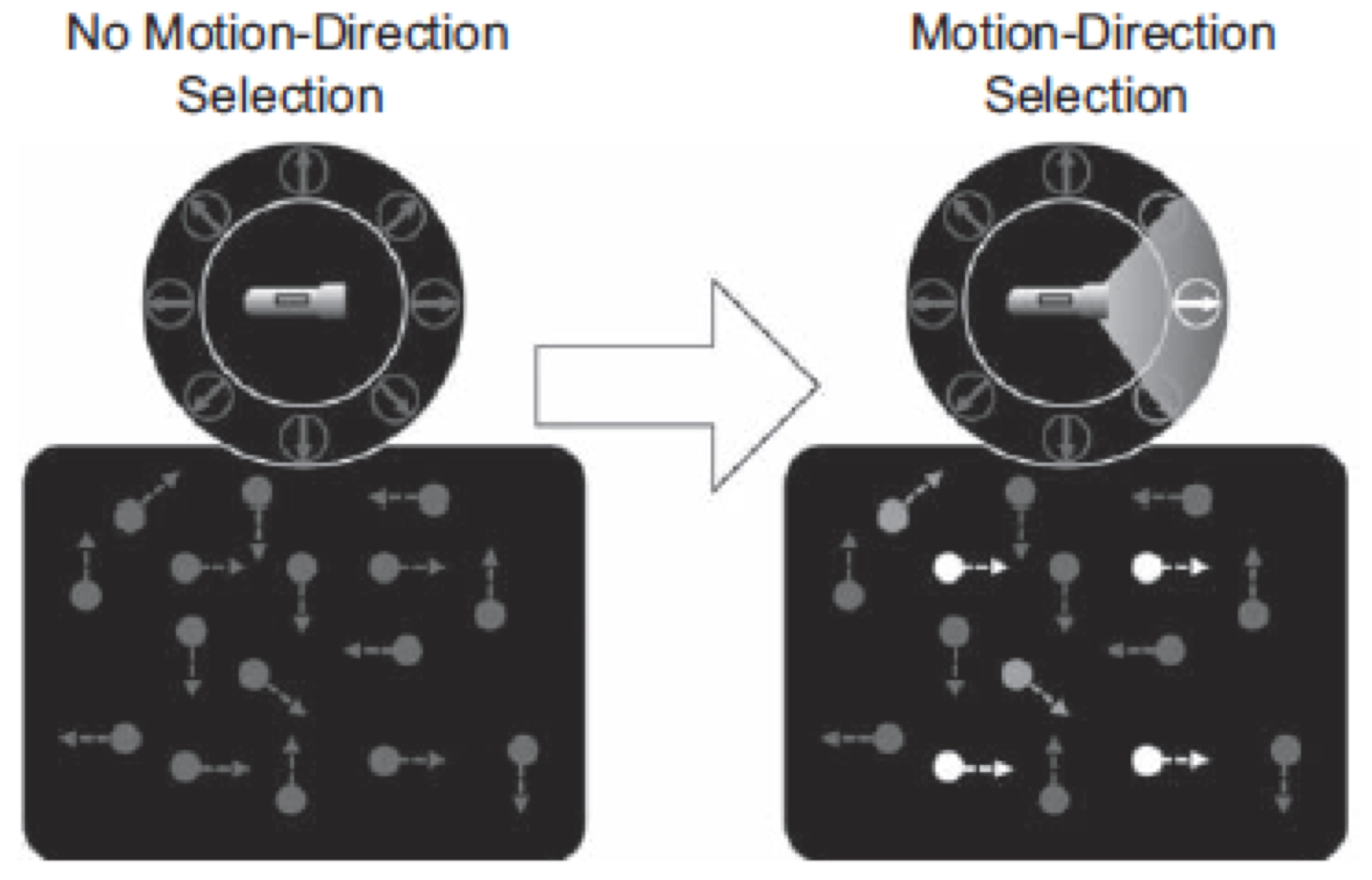
Figure: From Levinthal & Franconeri (in press). The ring at top represents different motion directions that might be amplified by the ‘spotlight’. At left, without attending a direction of motion, all moving elements in the lower image would be processed together, and there would be no common fate grouping. At right, as a consequence of selecting a direction of motion, target elements are enhanced, forming a common fate group
Click here for more information (including movies) on these experiments.