Visual Thinking Lab
We study visual thinking: how it works, and how education + design can make it work better.

Redundant Encoding
Download PDF
Collaborators: Christine Nothelfer1, Michael Gleicher2, Steven Franconeri1
1Department of Psychology, Northwestern University, 2Department of Computer Sciences, University of Wisconsin - Madison
The redundant use of multiple visual features (redundant encoding) is a common data visualization technique. However, there is surprisingly very little evidence that there is a benefit to adding such visual complexity. Here we tested whether selection performance is better for simultaneous selection of multiple dimensions (color and shape) that specify the same set, relative to selection of either dimension alone. That is, is conjunctive selection helpful, even when the extra dimension is redundant? Below is a summary of our study.
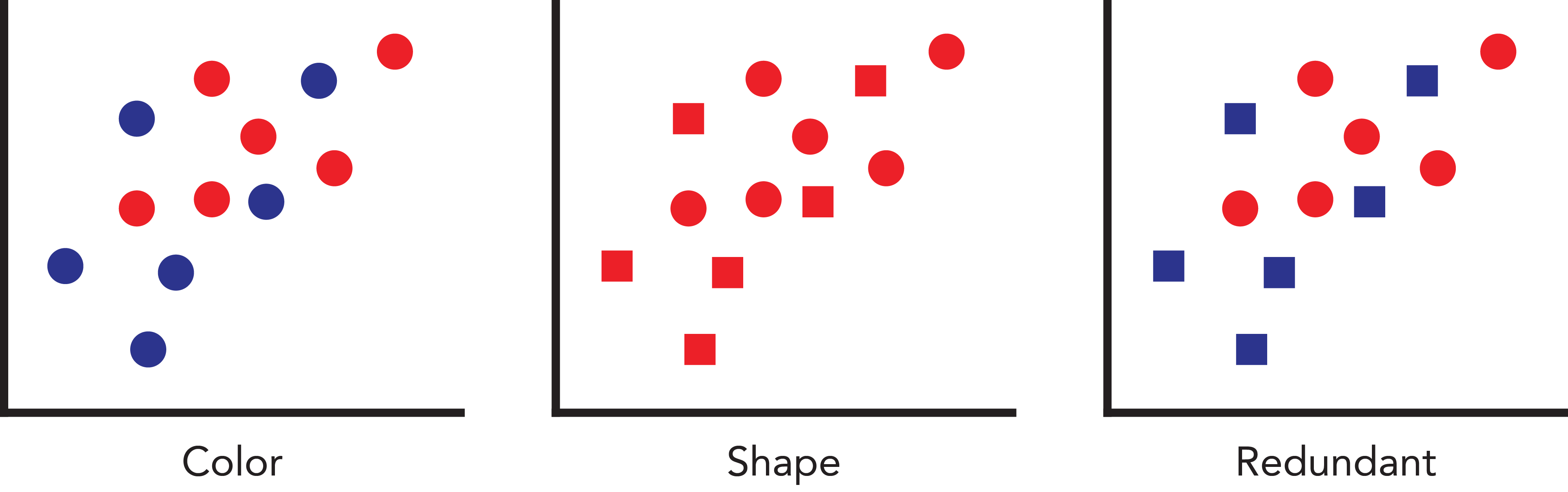
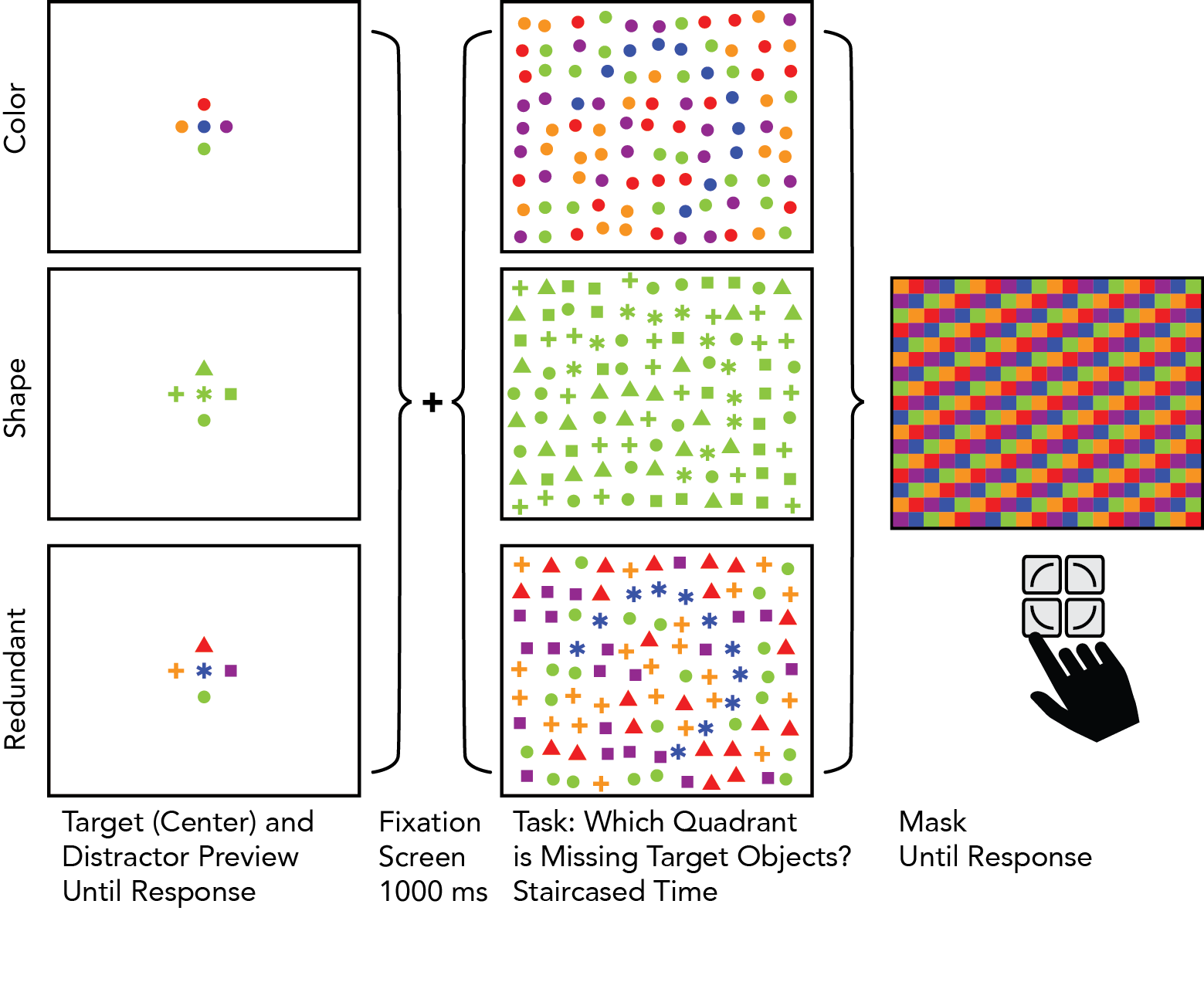
Take-away 1: Visual selection is better with redundant encoding
When participants were asked to simultaneously visually select a large set of objects and indicate the global shape of a set of target objects, accuracy was much higher when those objects were redundantly encoded by color and shape (88%, across 3 experiments) than when those objects were encoded by color alone (66%) and shape alone (58%). This suggests that visual selection is better when selecting redundantly encoded objects. Further, this task was remarkably accomplished with a very brief (staircased) display time (M=89ms, SD=32ms).
Take-away 2: Grouping is stronger with redundant encoding
To investigate whether the redundancy benefit generalizes to other tasks, we used the repetition discrimination task (Palmer & Beck, 2007), which assesses the strength of a grouping cue. We tested grouping by luminance similarity, shape similarity, and (redundant) luminance combined with shape similarity. Grouping strength is assessed as the difference in response time to detecting the repeated letter (A or H) when it occurs within a group vs between groups. Our results revealed that grouping is much stronger when objects are redundantly encoded by luminance & shape, than when encoded by either dimension alone.

Implications
These findings have implications for the way that we encode features in data visualization (e.g., when graphing software such as Microsoft Excel defaults to redundant shape/color conjunctions in graph glyphs). More broadly, this result applies to how we attend to objects in our daily environment – it is much more likely that an object will differ from its surrounding objects in multiple feature dimensions than a single feature dimension.
Try it out yourself